RapidMiner AI Finance Model - III
** There are NEW livestream videos about RapidMiner! Visit my Channel here **
In Lesson 2, I went over the concept of MultiObjective Feature Selection (MOFS). In this lesson we’ll build on MOFS for our model but we’ll forecast the trend and measure it’s accuracy.
Revisiting Mofs
We learned in lesson 2 that RapidMiner can simultaneously select the best features in your data set while maximizing the performance. We ran the process and the best features were selected below.
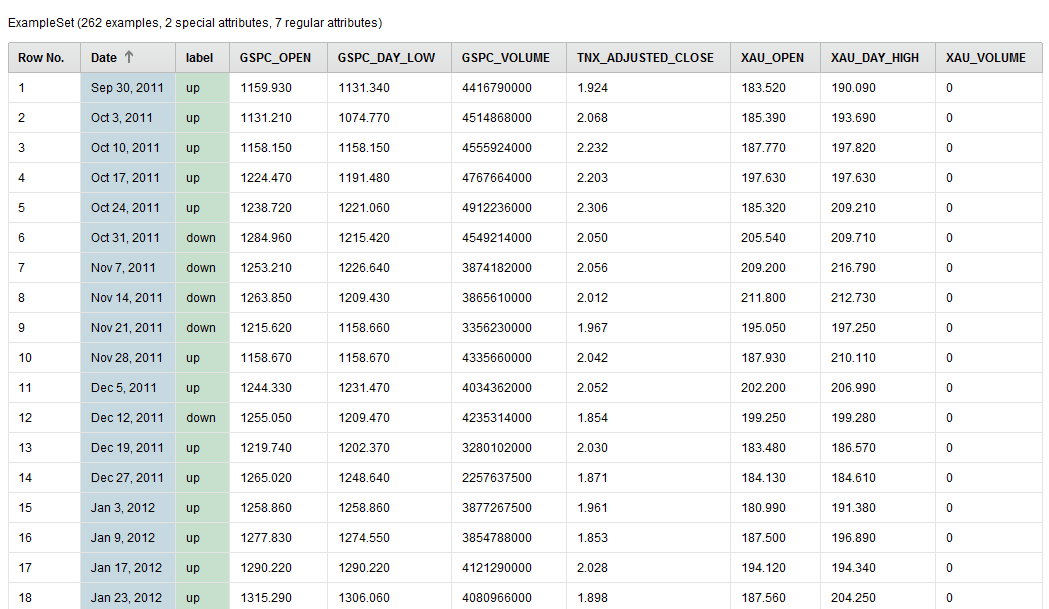 MultiObjective Feature Selection
MultiObjective Feature Selection
From here we want to feed the data into three new operators that are part of the Series Extension. We will be using the Windowing, Sliding Window Validation, and the Forecasting Performance operator.
These there operators are key to measure a performance of your time series model. RapidMiner is really good and determining the directional accuracy of time series and a bit rough when it comes to point forecasts. My personal observation is that it’s futile to get a point forecast for an asset price, you have better luck with direction and volatility.
Our forecasting model will use a Support Vector Machine and and RBF kernel. Time series appear to benefit from this combination and you can always check out this link for more info.
Forecast Trend Accuracy
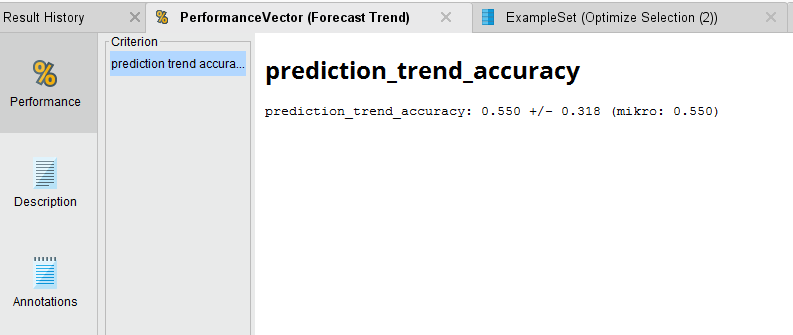 Forecast Trend Accuracy
Forecast Trend Accuracy
The Process
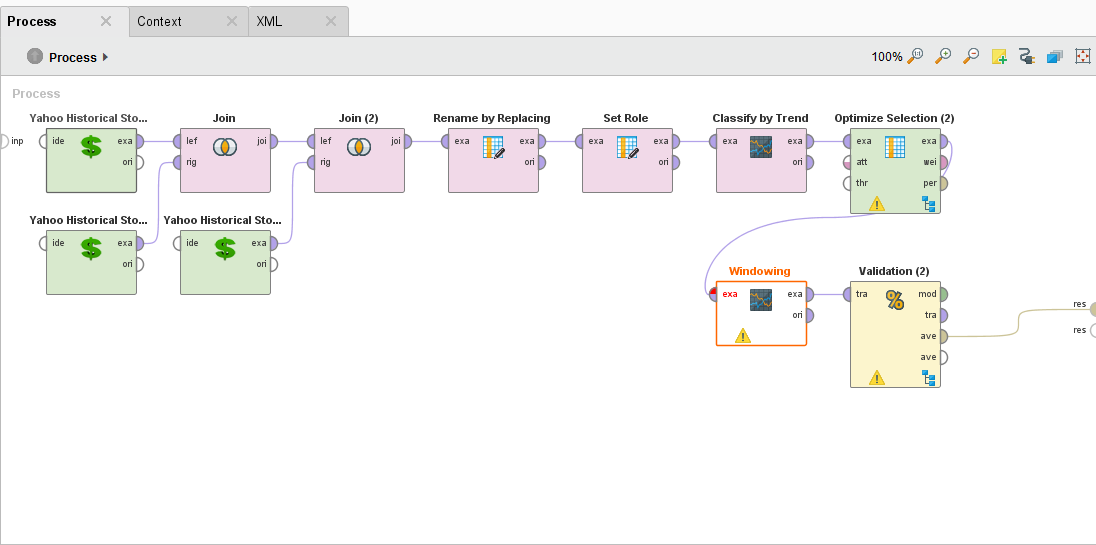 Forecast Trend Accuracy Process
Forecast Trend Accuracy Process
Sliding Window Validation Parameters
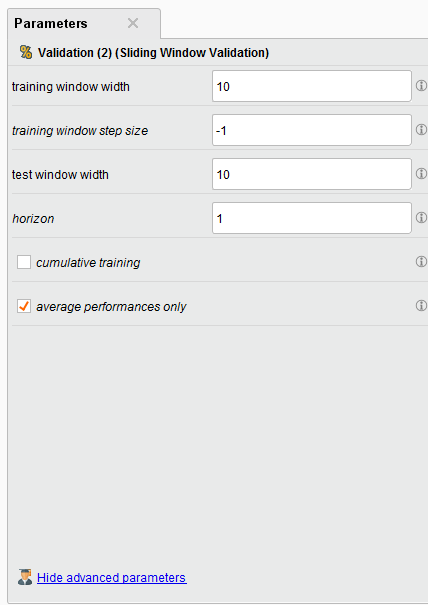 Sliding Window Parameters
Sliding Window Parameters
Windowing the Data
RapidMiner allows you to do multivariate time series analysis also known as a model driven approach to analysis. This is different than a data driven approach, such as ARIMA, and allows you to use many different inputs to make a forecast. Of course, this means that point forecasting becomes very difficult when you have multiple inputs, but makes directional forecast more robust.
The model driven approach in RapidMiner requires you to Window your Data. To do that you’ll need to use the Window operator. This operator is often misunderstood, so I suggest you read my post in the community on how it works.
Tip: Another great reference on using RapidMiner for time series is here.
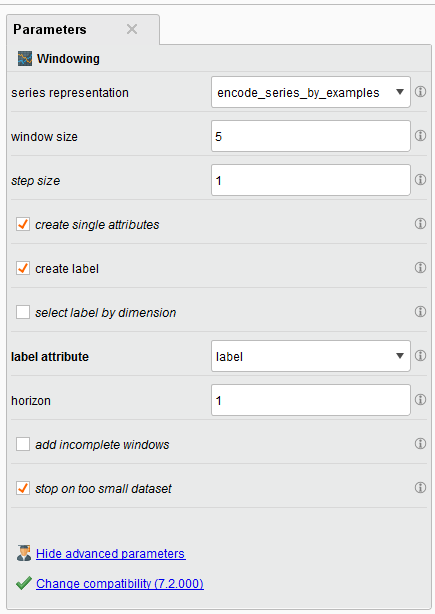
There are key parameters that you should be aware of especially the window size, the step size, whether or not you create a label, and the horizon.
 Optimization parameters
Optimization parameters
When it comes to time series for the stock market, I usually choose a value of 5 for my window. This can be fore 5 days, if your data is daily, or 5 weeks if it’s weekly. You can choose what you think is best.
The Step Size parameter tells the Windowing operator to create a new window with the next example row it encounters. If it was set to two, then it will move two examples ahead and make a new window.
Tip: The Series Representation parameter is defaulted to “encode_series_by_examples.” You should leave this default if your time series data is row by row. If a new value of your time series data is in a new column (e.g. many columns and one row), then you should change it to “encode_series_by_attributes.”
Sliding Validation
The Sliding Window Validation operator is what is used to backtest your time series, it operates differently than a Cross Validation because it creates a “time window” on your data, builds a model, and tests it’s performance before sliding to another time point in your time series.
Sliding Window Parameters
In our example we create a training and testing window width of 10 example rows, our step size is -1 (which is the size of the last testing window), and our horizon is 1. The horizon is how far into the future we want to predict, in this case it’s 1 example row.
There are some other interesting toggle parameters to choose from. The default is average performances only, so your Forecast Trend Accuracy will be your average performance. If you toggle on “cumulative training” then the Sliding Window Validation operator will keep adding the previous window to the training set. This is handy if you want see if the past time series data might affect your performance going forward BUT it makes training and testing very memory intensive.
Double clicking on the Sliding Window Validation operator we see a typical RapidMiner Validation training and testing sides where we can embed our SVM, Apply Model, and Forecasting Performance operators. The Forecasting Performance operator is a special Series Extension operator. You need to use this to forecast the trend on any time series problem.
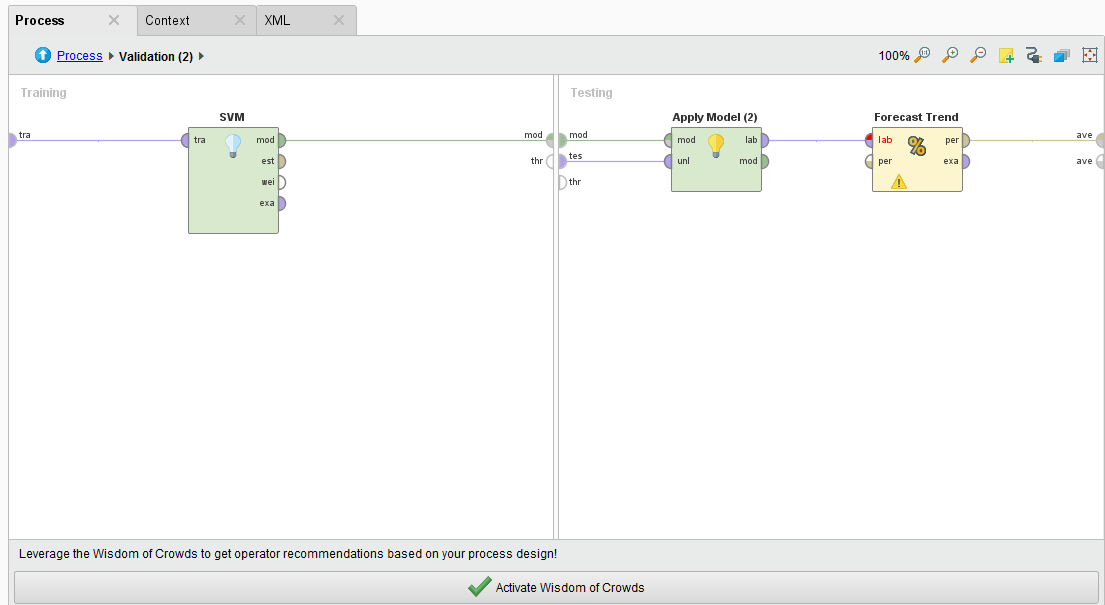 Sliding Window Guts
Sliding Window Guts
Forecast the Trend
Once we run the process and the analysis completes, we see that we have a 55.5% average accuracy to predict the direction of the trend. Not great, but we can see if we can optimize the SVM parameters of C and gamma to get better performance out of the model.
Forecast Trend Accuracy
In my next lesson I’ll go over how to do Optimization in RapidMiner to better forecast the trend.
That’s the end of Lesson 3 for your first AI financial market model. You can download the above sample process here. To install it, just go to File > Import Process. Lesson 4 will be updated shortly.
This is an update to my original 2007 YALE tutorials and are updated for RapidMiner v7.0. In the original set of posts I used the term AI when I really meant Machine Learning.